"Fill in the Middle (FIM)"이라는 pretraining idea에서 출발한 연구

- Related Work
- FIM
- 문장을 세부분으로 나눈다: prefix, middle, suffix
- suffix, prefix, middle의 배치로 하고, middle을 예측하도록 학습한다.
- 하지만 이 방법은 문제점이 몇가지 있다.
- suffix, prefix의 context 연결이 자연스럽지 않은 것
- LM 생성은 일반적으로 최근 생성한 몇가지 토큰에 대해 바이어스 되는 경향이 있음
- 문장은 prefix, middle, suffix를 무작위적으로 스플릿하는데, 그렇기 때문에 문장 전체를 못봄
(이건 약간 동의하기 힘들다)
- Bidirectional Language Modeling과 MIM의 차이
- 제안 방법 "Meet in the Middle (MIM)"은 기존 Bidirectional LM과 달리 autoregressive
- 하나의 확률을 내뱉지 않고, forward, backward 두가지 확률을 내뱉음
- FIM
- Method
- 2개 목표를 달성하기 위해 2개의 모델을 학습
- 1) prefix, suffix 방향으로 각각 next token을 예측하도록 학습
- 2) 각각의 방향으로부터 나온 각 토큰의 생성 확률을 일치시키도록 규제 부여 (L1 loss)
- Synchronous Bidirectional Attention 적용
- attention layer output을 역방향 생성 토큰의 해당 step을 람다만큼 더해준다.
- 람다 0.3일때 좋았다고 함
- 2개 목표를 달성하기 위해 2개의 모델을 학습



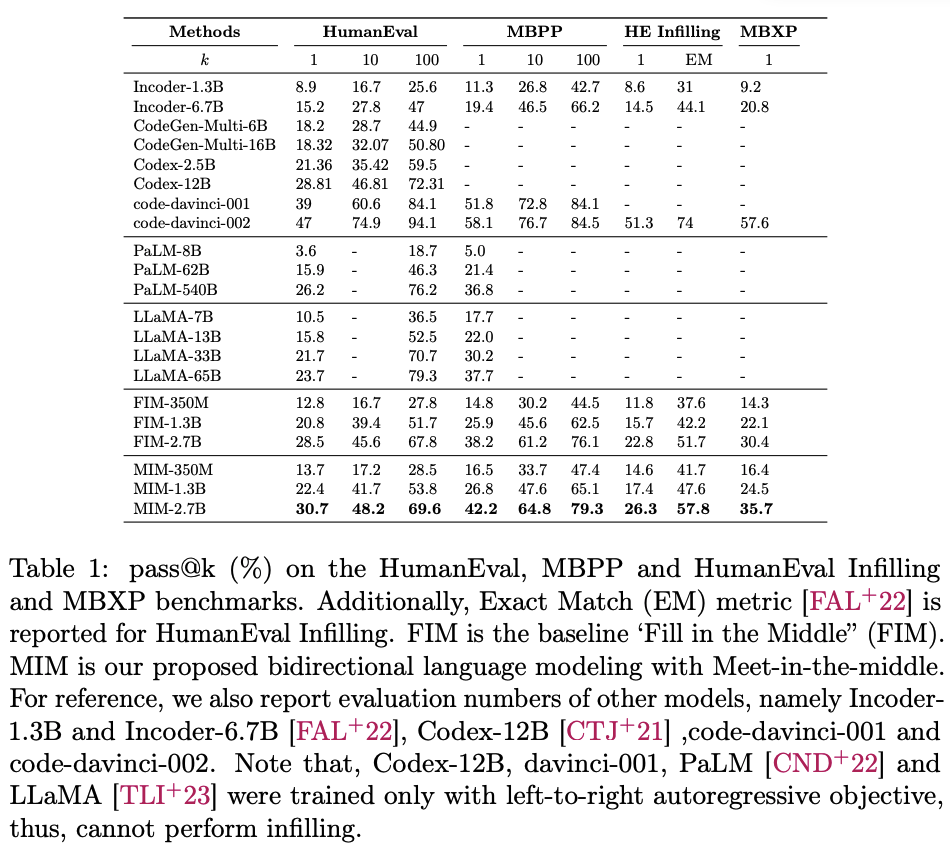
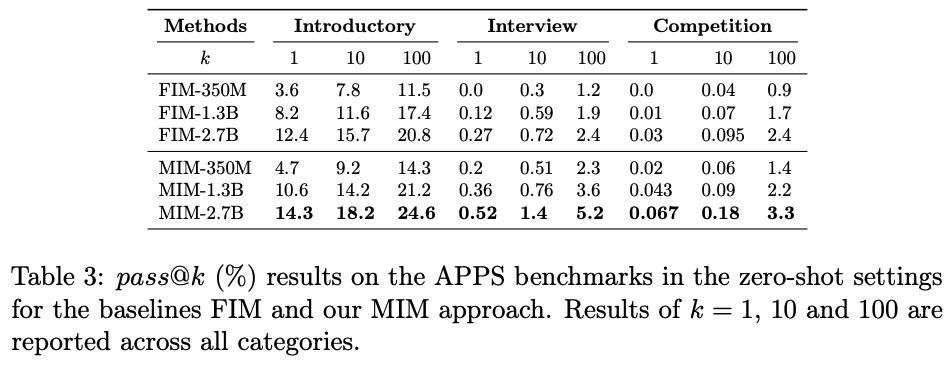
- 실험 결과

'딥러닝 > NLP' 카테고리의 다른 글
| Code Generation Survey 요약 정리 (0) | 2021.05.20 |
|---|